The Apryse SDK offers deep, programmatic access to PDF content—so you can extract exactly what you need, fast.
Key capabilities include:
Text Extraction: Pull structured Unicode text with style, position, and layout details using pdftron.PDF.TextExtractor. Advanced options include ligature expansion, hidden/duplicated text handling, and more.
Signature Extraction: Retrieve digital signatures, timestamps, and verification details.
Graphics-Level Access: Extract and analyze graphical elements, including paths, color spaces, dash patterns, and transparency settings.
Low-Level Character Data: Access exact positioning of text runs and individual characters for precise downstream processing.
Font and Glyph Access: Extract embedded fonts and glyph outlines for advanced rendering or analysis.
Image Extraction: Extract all embedded images, with support for all PDF compression filters—including optional RAW output and color normalization.
Layer (OCG) Extraction: Programmatically access PDF layers and optional content groups.
Annotations and Forms: Retrieve all form fields, annotations, and widget data directly from the document.
Tagged PDF Support: Access marked content for tagged PDFs, enabling structure-aware extraction.
Metadata Access: Read document metadata for title, author, keywords, and more.
Text Extraction
To extract text from a PDF document.
Text extraction reading ordering is not defined in the ISO PDF standard. In fact, there is no concept of sentence, paragraph, tables, or anything similar in a typical PDF file. This means each PDF vendor is left to their own design/solution and will extract text with some differences. Therefore, reading order is not guaranteed to match the order that a typical user reading the document would follow.
The reading order of a magazine, newspaper article, and an academic article are all quite different due to the lack of semantic information in a PDF and the placement/ordering of text in the document. Where different users may have different expectations of the correct reading order.
1PDFDoc doc = new PDFDoc(filename)
2Page page = doc.GetPage(1);
3
4TextExtractor txt = new TextExtractor();
5txt.Begin(page);
6
7// Extract words one by one.
8TextExtractor.Word word;
9for (TextExtractor.Line line = txt.GetFirstLine(); line.IsValid(); line=line.GetNextLine())
10{
11 for (word=line.GetFirstWord(); word.IsValid(); word=word.GetNextWord())
12 {
13 //word.GetString();
14 }
15}
1PDFDoc doc(filename);
2Page page = doc.GetPage(1);
3
4TextExtractor txt;
5txt.Begin(page); // Read the page.
6
7// Extract words one by one.
8TextExtractor::Line line = txt.GetFirstLine();
9TextExtractor::Word word;
10for (; line.IsValid(); line=line.GetNextLine())
11{
12 for (word=line.GetFirstWord(); word.IsValid(); word=word.GetNextWord())
13 {
14 //word.GetString();
15 }
16}
1doc := NewPDFDoc(filename)
2page := doc.GetPage(1)
3
4txt := NewTextExtractor()
5txt.Begin(page) // Read the page
6
7// Extract words one by one.
8word := NewWord()
9line := txt.GetFirstLine()
10for line.IsValid(){
11 word = line.GetFirstWord()
12 for word.IsValid(){
13 //wordString := word.GetString()
14 word = word.GetNextWord()
15 }
16 line = line.GetNextLine()
17}
1PDFDoc doc = new PDFDoc(filename);
2Page page = doc.getPage(1);
3
4TextExtractor txt = new TextExtractor();
5txt.begin(page); // Read the page.
6
7// Extract words one by one.
8TextExtractor.Word word;
9for (TextExtractor.Line line = txt.getFirstLine(); line.isValid(); line = line.getNextLine())
10{
11 for (word = line.getFirstWord(); word.isValid(); word = word.getNextWord())
7Dim textData As String = txt.GetTextUnderAnnot(annotation)
About extracting text
When we use the ElementReader class to read elements from a PDF document, we are often faced with data that is partial. For example, let us say that we are attempting to extract a sentence that says "This is a sample sentence." from a PDF document. We could potentially end up with two elements - "T" and "his is a sample sentence.". This is possible because in a PDF document, text objects are not always cleanly organized into words sentences, or paragraphs. The ElementReader class will return Element objects exactly as they are defined in the PDF page content stream.
Text runs
An element of type e_text directly corresponds to a Tj element in the PDF document. Each e_text element represents a text run, which represents a sequence of text glyphs that use the same font and graphics attributes. Say, if there is a single word, whose letters are each presented with a different font, then each letter would be a separate text run. You may also encounter text runs that contain multiple words separated by spaces. The PDF format does not guarantee that the text will be presented in reading order.
TextExtractor class
All this just goes to say that attempting to use an ElementReader to extract text data from a PDF document is not guaranteed to return data in the order expected (reading order). The most straightforward approach to extract words and text from text-runs is using the pdftron.PDF.TextExtractor class, as shown in the TextExtract sample project - TextExtract Sample
TextExtractor will assemble words, lines, and paragraphs, remove duplicate strings, reconstruct text reading order, etc. Using TextExtractor you can also obtain bounding boxes for each word, line, or paragraph (along with style information such as font, color, etc). This information can be used to search for corresponding text elements using ElementReader.
Image Extraction
To extract image content from a PDF document.
1PDFDoc doc = new PDFDoc(filename);
2ElementReader reader = new ElementReader();
3
4// Read page content on every page in the document
22 $image->Export($output_filename); // or ExportAsTiff or ExportAsPng
23 // optionally, you can also extract uncompressed/compressed
24 // image data directly using element->GetImageData()
25 }
26 case Element::e_form:
27 {
28 $reader->FormBegin();
29 ProcessElements($reader);
30 $reader->End();
31 }
32 }
33 }
34}
1doc = PDFDoc(filename)
2reader = ElementReader()
3
4itr = doc.GetPageIterator()
5while itr.HasNext():
6 # Read the page
7 reader.Begin(itr.Current())
8 ProcessElements(reader)
9 reader.End()
10 itr.Next()
11
12def ProcessElements(reader):
13 # Traverse the page display list
14 element = reader.Next()
15 while element != None:
16 type = element.GetType()
17 if type == Element.e_image:
18 image = Image(element.GetXObject())
19 image.Export(path) # or ExportAsTiff or ExportAsPng
20 # optionally, you can also extract uncompressed/compressed
21 # image data directly using element.GetImageData()
22 elif type == Element.e_form:
23 reader.FormBegin()
24 ProcessElements(reader)
25 reader.End()
26 element = reader.Next()
1doc = PDFDoc.new(filename)
2reader = ElementReader.new()
3
4itr = doc.GetPageIterator()
5while itr.HasNext() do
6 # Read the page
7 reader.Begin(itr.Current())
8 ProcessElements(reader)
9 reader.End()
10 itr.Next()
11end
12
13def ProcessElements(reader)
14 # Traverse the page display list
15 element = reader.Next()
16 while !element.nil? do
17 type = element.GetType()
18 case type
19 when Element::E_image
20 image = Image.new(element.GetXObject())
21 image.Export(path) # or ExportAsTiff or ExportAsPng
22 # optionally, you can also extract uncompressed/compressed
23 # image data directly using element.GetImageData()
24 when Element::E_form:
25 reader.FormBegin()
26 ProcessElements(reader)
27 reader.End()
28 end
29 end
30end
1Dim doc As PDFDoc = New PDFDoc(filename)
2Dim reader As ElementReader = New ElementReader
3
4Dim itr As PageIterator = doc.GetPageIterator()
5While itr.HasNext()
6 ' Read the page
7 reader.Begin(itr.Current())
8 ProcessElements(reader)
9 reader.End()
10End While
11
12Sub ProcessElements(ByVal reader As ElementReader)
13 ' Traverse the page display list
14 Dim element As Element = reader.Next()
15 While Not IsNothing(element)
16 If element.GetType() = element.Type.e_image Then
17 Dim image As PDFTRON.PDF.Image = New PDFTRON.PDF.Image(element.GetXObject())
18 image.Export(output_filename) ' or ExporAsPng() or ExporAsTiff() ...
19 ' optionally, you can also extract uncompressed/compressed
20 ' image data directly using element.GetImageData()
21 ElseIf element.GetType() = element.Type.e_form Then
22 reader.FormBegin()
23 ProcessElements(reader)
24 reader.End()
25 End If
26 element = reader.Next()
27 End While
28End Sub
PDF image extraction Full code sample which illustrates a few approaches to PDF image extraction.
About reading page content
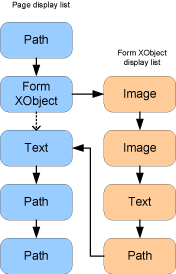
Page content is represented as a sequence of graphical Elements such as paths, text, images, and forms. The only effect of the ordering of Elements in the display list is the order in which Elements are painted. Elements that occur later in the display list can obscure earlier elements.
A display list can be traversed using an ElementReader object. To start traversing the display list, call reader.Begin(). Then, reader.Next() will return subsequent Elements until null is returned (marking the end of the display list).
While ElementReader only works with one page at a time, the same ElementReader object may be reused to process multiple pages.
About Form XObjects, Type3 font glyphs, and tiling patterns
A PDF page display list may contain child display lists of Form XObjects, Type3 font glyphs, and tiling patterns. A form XObject is a self-contained description of any sequence of graphics objects (such as path objects, text objects, and sampled images), defined as a PDF content stream. It may be painted multiple times — either on several pages or at several locations on the same page — and will produce the same results each time (subject only to the graphics state at the time the Form XObject is painted). In order to open a child display list for a Form XObject, call the reader.FormBegin() method. To return processing to the parent display list call reader.End(). Processing of the Form XObject display (traversing the child display list) is illustrated below.
Note that, in the above sample code, a child display list is opened when an element with type Element.ElementType.e_form is encountered by the reader.FormBegin() method. The child display list becomes the current display list until it is closed using reader.End(). At this point the processing is returned to the parent display list and the next Element returned will be the Element following the Form XObject. Also note that, because Form XObjects may be nested, a sub-display list could have its own child display lists. The sample above shows traversing these nested Form XObjects recursively.
Similarly, a pattern display list can be opened using reader.PatternBegin(), and a Type3 glyph display list can be opened using the reader.Type3FontBegin() method.
Embedded Form Extraction
To extract embedded fonts in a document.
1boolean ObjIsEmbeddedFont(Obj indirectObj) {
2 if (indirectObj.IsFree()) {
3 return false;
4 }
5
6 if (!indirectObj.IsDict() && !indirectObj.IsStream()) {
21 if (!is_null($subtypeObj) && $subtypeObj->IsName()) {
22 $subtypeName = $subtypeObj->GetName();
23 if (strcmp($subtypeName, "CIDFontType0")) {
24 return false;
25 }
26 }
27
28 $font = new Font($indirectObj);
29 return $font->IsEmbedded();
30}
31
32$doc = new PDFDoc($filename);
33$sdfdoc = $doc->GetSDFDoc();
34for ($i = 1; $i < $sdfdoc->XRefSize(); $i++) {
35 $indirectObj = $sdfdoc->GetObj($i);
36 if(objIsEmbeddedFont($indirectObj)) {
37 // perform document processing
38 }
39}
1def obj_is_embedded_font(indirect_obj):
2 if indirect_obj.IsFree():
3 return False
4
5 if not indirect_obj.IsDict() and not indirect_obj.IsStream():
6 return False
7
8 type_obj = indirect_obj.FindObj("Type")
9 if type_obj is None or not type_obj.IsName():
10 return False
11
12 type_name = type_obj.GetName()
13 if type_name != "Font":
14 return False
15
16 subtype_obj = indirect_obj.FindObj("Subtype")
17 if subtype_obj is not None and subtype_obj.IsName():
18 subtype_name = subtype_obj.GetName()
19 if subtype_name =="CIDFontType0":
20 return False
21
22 font = Font(indirect_obj)
23 return font.IsEmbedded()
24
25doc = PDFDoc(filename)
26sdfdoc = doc.GetSDFDoc()
27for i in range(1, sdfdoc.XRefSize() + 1):
28 indirect_obj = sdfdoc.GetObj(i)
29 if obj_is_embedded_font(indirect_obj):
30 # perform document processing
1def obj_is_embedded_font(indirect_obj)
2 if indirect_obj.IsFree() then
3 return false
4 elsif !indirect_obj.IsDict() && !indirect_obj.IsStream() then
5 return false
6 end
7
8 type_obj = indirect_obj.FindObj("Type")
9 if type_obj.nil? || !type_obj.IsName() then
10 return false
11 end
12
13 type_name = type_obj.GetName()
14 if type_name != "Font" then
15 return false
16 end
17
18 subtype_obj = indirect_obj.FindObj("Subtype")
19 if !subtype_obj.nil? && subtype_obj.IsName() then
20 subtype_name = subtype_obj.GetName()
21 if subtype_name =="CIDFontType0" then
22 return false
23 end
24 end
25
26 font = Font.new(indirect_obj)
27 return font.IsEmbedded()
28
29end
30
31doc = PDFDoc.new(filename)
32sdfdoc = doc.GetSDFDoc()
33for i in 1..sdfdoc.XRefSize() do
34 indirect_obj = sdfdoc.GetObj(i)
35 if obj_is_embedded_font(indirect_obj) then
36 # perform document processing
37 end
38end
1Function ObjIsEmbeddedFont(indirectObj As Obj) As Boolean
2 If indirectObj.IsFree() Then
3 Return False
4 ElseIf Not indirectObj.IsDict() And Not indirectObj.IsStream() Then
5 Return False
6 End if
7
8 Dim typeObj As Obj = indirectObj.FindObj("Type")
9 If typeObj Is Nothing Then
10 Return False
11 ElseIf Not indirectObj.FindObj("Type").IsName() Then
12 Return False
13 ElseIf indirectObj.FindObj("Type").GetName() <> "Font" Then
14 Return False
15 ElseIf indirectObj.FindObj("Subtype") IsNot Nothing And indirectObj.FindObj("Subtype").IsName()
16 If indirectObj.FindObj("Subtype").GetName() = "CIDFontType0" Then
17 Return False
18 End If
19 End If
20
21 Dim font As Font = New Font(indirectObj)
22 Console.WriteLine(font.IsEmbedded())
23 Return font.IsEmbedded()
24End Function
25
26PDFDoc = New PDFDoc(filename)
27Dim sdfdoc As SDFDoc = doc.GetSDFDoc()
28Dim XRefSize As Integer = sdfdoc.XRefSize()
29Dim i As Integer
30For i = 1 To XRefSize
31 Dim indirectObj As Obj = sdfdoc.GetObj(i)
32 If ObjIsEmbeddedFont(indirectObj) Then
33 ' perform document processing
34 End If
35Next i
About embedded fonts
PDF documents access fonts from one of two places: the host machine rendering the PDF document or from within the PDF document itself. When a font is used in a PDF document which is not available on the machine loading that document and it's not embedded within the document the viewer will usually load a different font. When that font is contained within the PDF document itself we call that an embedded font. When a PDF contains an embedded font that font can still be rendered even if it is not defined on the host machine.
All font information in a PDF is stored in the SDF layer as an SDF object and exists as either a dictionary or a stream. When a font exists a dictionary that means that means that it is defined exclusively within the PDF document but if it is defined as a stream that means it exists as a file which may or may not exist within the PDF document itself. It is possible for either type to be embedded.
It's also possible to programatically embed fonts within a PDF with the Apryse SDK. You can find an example in the ElementBuilder sample code.
The samples below demonstrates how to iterate over all embedded fonts found within a PDF document. Note that because this requires several low-level operations additional care must be taken for to check for possible null pointers. Also note that fonts with the subtype CIDFontType0 are not not counted as embedded fonts because they are necessarily referenced by a parent font within the same document.