Apryse's semantic comparison feature enables the visualization of textual differences between two related PDF documents. The text processing is based on natural reading order, highlighting the differences as colored annotations.
The comparison is always performed between two versions of a document. The older version is called the Before file (document 1), while the new version is the After file (document 2).
A difference is defined as a consecutive block of text that was inserted, deleted or modified. Differences always come in pairs. When some text is deleted from the Before side, a corresponding placeholder is inserted into the After side to indicate the position where the text was deleted from.
Similarly, when some text is inserted into the After side, a corresponding placeholder is generated for the Before side to help identify its location of insertion.
Finally, when content is modified, the difference comes out as a pair of annotations consisting of a deletion on the Before side and an insertion on the After side.
These difference annotations are labeled with a unique identifier, so they can be paired up side-by-side at the application level. We'll learn more about this later.
When entire lines are inserted or deleted, the placeholder at the opposite end is pictured as a horizontal line.
Usage
The HighlightTextDiff method takes two PDF documents as input, one being the Before (1) and the other one being the After (2) document. It compares them to find any differences, then overlays the highlight annotations on top of the input documents, which can in turn be saved to files.
1// Start with a PDFDoc (open source documents to compare)
2using (PDFDoc doc1 = new PDFDoc("compare_before.pdf"))
3using (PDFDoc doc2 = new PDFDoc("compare_after.pdf"))
4{
5 // Create an options object
6 TextDiffOptions options = new TextDiffOptions();
7
8 // Compare and highlight text differences in doc1 and doc2
Note that HighlightTextDiff is a static method within PDFDoc. The method returns the number of differences found, where each contiguous block of change is considered a single difference. If the two documents are identical, the function returns 0 and no annotations are added.
When the input PDFs already contain annotations or widgets, they are first flattened. When the function finishes, all annotations represent actual differences of text.
Facing Pages
It is easy to see that the more words and paragraphs you keep inserting into the document, the longer the After version will become compared to the Before PDF. You can reach a point where page N in Before is no longer matching up with page N in After. If you were to display Before and After next to each other, you could start displaying unrelated content, and that can be quite confusing.
Yet in certain situations, you can assume that pages generally line up between Before and After, especially with short documents with few changes between them.
We actually offer two separate APIs, AppendTextDiff and HighlightTextDiff. Depending on the situation, one might be preferable to the other.
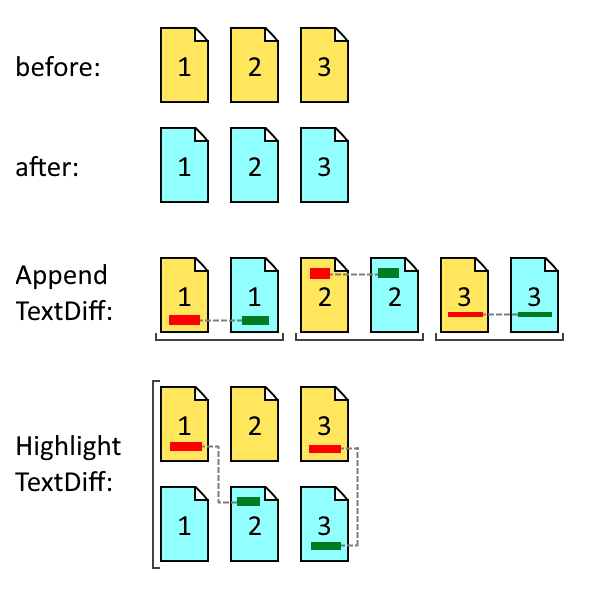
Consider that you have two versions of an input document, Before (yellow paper) and After (cyan paper):
The AppendTextDiff function generates a single output document where the Before and After pages are merged in an alternating order (page 1 of each, followed by page 2 of each, and so on). In this case, you are only saving a single output file, and you can use a single WebViewer in Double Page mode (also known as Two Page View in Acrobat), so that the same page numbers from the two versions are next to each other.
This is most suitable when you know that Before and After have approximately the same number of pages and the differences are on the small side. When one document is longer than the other, blank filler pages are automatically inserted, so that the last few pages will have a blank pair.
The advantage is that it's easy to use a single WebViewer and switch it into Double Page view, and a single output file contains both versions in a compact format. However, the Before and After sides can't be scrolled independently, and the left and right pages could get out of sync very soon.
The HighlightTextDiff function treats the two inputs independently, and inserts the highlights directly into the Before and After documents. In this case, you are saving two output files that require two WebViewer controls side-by-side. This way the two documents can scroll independently, so that insertions and deletions line up perfectly, even when the page numbers are way out of sync.
We've already seen sample code for HighlightTextDiff, here are some samples for AppendTextDiff:
1// Start with a PDFDoc (open source documents to compare)
2using (PDFDoc output = new PDFDoc())
3using (PDFDoc doc1 = new PDFDoc("compare_before.pdf"))
4using (PDFDoc doc2 = new PDFDoc("compare_after.pdf"))
5{
6 // Create an options object
7 TextDiffOptions options = new TextDiffOptions();
8 // Compare and highlight text differences in doc1 and doc2
Designers will be happy to learn that the Before and After annotation colors are customizable. Both the RGB value and the opacity can be adjusted. An opacity of 1.0 (100% opaque) can be too dark in combination with certain colors, in which case 0.5 (50% semi-transparent) may work better. An opacity value of 0.0 (full transparency) is completely invisible, so it makes sense to stay above values of 0.15.
The colors can be configured via the TextDiffOptions object. SetColorA and SetOpacityA control the Before document's annotation color. SetColorB and SetOpacityB adjust the After document's annotation color. Finally, the options object is passed to HighlightTextDiff as the third argument.
Sometimes the need arises to exclude certain areas from text differencing. Most typically, headers and footers can disrupt the flow of the logical content, which often shows up as fake differences. Another example may be an advertisement that should not be a part of the actual content, either.
For those reasons the semantic comparison API offers a way of setting up exclusion zones where text is not considered for comparison, so any differences will be ignored.
Note that rectangles use PDF coordinates (measured in points, 1 point = 1/72 inch; origin is the page's bottom-left corner).
Annotation Metadata
We mentioned earlier that differences always come in pairs, and each carries a unique numeric identifier starting at the number 1 by increments of 1. Highlight annotations sharing the same identifier in both documents correspond to each other.
In addition, each annotation also carries information about the type of difference it represents, which can be either insertion, deletion or edit.
Usually each difference is represented by a single annotation object, which may consist of one or more rectangles. However, in certain situations an insertion or deletion may wrap across page boundaries. In those cases a single difference can consist of more than one highlight annotation, one per page, all instances sharing the same identifier and difference type.
The identifier and type information are stored as metadata within the annotation object under two custom keys:
TextDiffID: a unique number shared between the two PDF documents.
TextDiffType: may be either insert, delete or edit.
The easiest way to retrieve this information is via the Annot.GetCustomData method:
1// Get page 1
2Page page1 = doc1.GetPage(1);
3// Get first annotation
4Annot annot1 = page1.GetAnnot(0);
5// Get custom data TextDiffID
6string id = annot1.GetCustomData("TextDiffID");
7// Get custom data TextDiffType
8string type = annot1.GetCustomData("TextDiffType");
1// Get page 1
2Page page1 = doc1.GetPage(1);
3// Get first annotation
4Annot annot1 = page1.GetAnnot(0);
5// Get custom data TextDiffID
6UString id = annot1.GetCustomData("TextDiffID");
7// Get custom data TextDiffType
8UString type = annot1.GetCustomData("TextDiffType");
1// Get page 1
2Page page1 = doc1.getPage(1);
3// Get first annotation
4Annot annot1 = page1.getAnnot(0);
5// Get custom data TextDiffID
6String id = annot1.getCustomData("TextDiffID");
7// Get custom data TextDiffType
8String type = annot1.getCustomData("TextDiffType");