Product:
Introduction to PDF file format
In this section, we present the basic structure of a PDF document. For details, please refer to the PDF Reference Manual. Below is a listing of a very simple PDF document. It displays a "Hello World" string on a single page.
sh
A PDF document consists of four sections:
- A one-line header identifying the version of the PDF specification to which the file conforms (Line 0). In the above sample, the header string is "%PDF-1.4". It identifies this file as a PDF document adhering to the 1.4 specification.
- A body containing the objects that make up the document contained in the file (Lines 1-45). Our sample file shows 6 objects each beginning with "obj" and ending with "endobj". Each object has its own number and a zero. The zero is the revision level (also known as the generation number) because PDF allows updates to the file to be made without rewriting the entire file.
- A cross-reference table containing information about the indirect objects in the file (Lines 46-54). The cross-reference table in our sample notes that it contains 7 entries; a dummy for object zero and one for each of the 6 objects. The table maps implicit object index into a byte offset from the beginning of the file to the location where the object is located. For example, Object 1 is represented first indicating that it begins at byte 9; Object 3 is represented with the fourth entry indicating that it is located at byte 204 in the file. etc.
- A trailer giving the location of the cross-reference table and of certain special objects within the body of the file (Lines 55-61).
Note that objects refer to each other using a notation like "5 0 R". The "R" stands for reference and uses the two preceding numbers to name a specific object and revision.
Therefore, the file body consists of a collection of objects, each object potentially referencing any or all objects, including itself. This set of nodes and directed references constitutes a graph. We could represent the "Hello World" sample file using the following abstract graph representation.
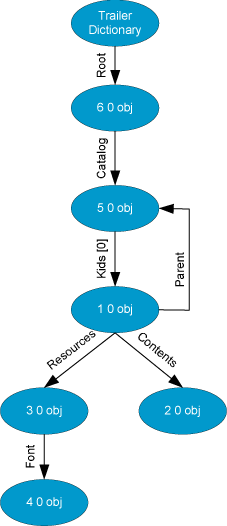
Each object in the graph is represented with an ellipse and each object cross reference is represented with an arrow.
Each PDF document must have a "Root" node. It must reference a "Catalog" node which must reference a "Pages" node. The "Pages" node further branches and points to each of the pages in the document. Note that a "Pages" node points to a group of pages whereas a "Page" node represents a single page.
The "Page" node references the page's "Contents" and the page's "Resources". The resource dictionary, in turn, references the "Fonts" used on the page. The resource dictionary can reference many other resource types, including Color Spaces, Patterns, Shadings, Images, Forms, and more. The page contents stream contains markup operators used to draw the page.
Each PDF document uses this basic object structure to represent a PDF document.
Before going into details of Apryse SDK SDF/COS object model, we should review the basics. For a detailed description of the SDF syntax and semantics, please refer to Chapter 3 (Syntax) of the PDF Reference Manual.
In PDF there are five atomic objects:
Object Type | Description | Samples |
|---|---|---|
Number | PDF provides two types of numeric object: integer and real. | 1.03 612 |
Bool | Boolean objects are identified by the keywords true and false. | true false |
Name | A name object is an atomic symbol uniquely defined by a sequence of characters. Names always begin with "/" and can contain letters and numbers and a few special characters. | /Font /Info /PDFNet |
String | Strings are sequences of bytes enclosed in "(" and ")" | (Hello World!) |
Null | The null object has a type and value that are unequal to those of any other object. Usually it refers to a missing object. | null |
Also, there are three compound objects:
Object Type | Description | Samples |
|---|---|---|
Array | An array object is a one-dimensional collection of objects arranged sequentially. Unlike arrays in typical computer languages, PDF arrays may be heterogeneous; that is, an array's elements may be any combination of numbers, strings, dictionaries, or any other objects, including other arrays. | [ true /Name ] |
Dictionary | A dictionary object is a map containing pairs of objects, known as the dictionary's entries. The first element of each entry is the key and the second element is the value. The key must be a name. The value can be any kind of object, including another dictionary. | <</key /value >> |
Stream | A stream is essentially a dictionary followed by a sequence of bytes. PDF streams are always indirect objects and thus always may be shared. | 1 0 obj << /Length 144 >> stream ........... endstream endobj |
Objects can be arbitrarily nested using the dictionary and array compounding operations.
All of the objects in the above tables are "direct objects" because they are not surrounded by "obj" and "endobj" keywords. The body of the PDF document is actually made up of a sequence of "indirect objects". An indirect object is created by taking a single direct object (whether it be atomic or compound) and enclosing it with the "nm obj" and "endobj" keywords (where n and m are non-negative integers).
Note that, because indirect objects are numbered and can be referenced by other objects, they can be shared — that is, referenced by more than one other object. However, since direct objects are not numbered, they can't be shared.
In the above PDF example, the object "3 0 obj" is an indirect object because the "obj" and "endobj" keywords wrap a dictionary object containing two entries.
sh
The "ProcSet" key is mapped to an array which is a direct object containing atomic direct objects. In a similar way, the "Font" key is mapped to a direct dictionary. On the other hand, "F1" in the inner dictionary is mapped to an indirect object with object number 4 and generation number 0. Because the "Font" key points to an indirect object, the same font resource can be shared across many different pages.
Did you find this helpful?
Trial setup questions?
Ask experts on DiscordNeed other help?
Contact SupportPricing or product questions?
Contact Sales