Product:
Examples of how to convert PDF to SVG using command-line
Apryse's PDF2SVG is a command-line application designed to convert PDF files to SVG, the open-standard W3C recommendation for high-end graphics on the web. The flawless conversion process creates web-ready SVG documents. This section covers the basic use of PDF2SVG explaining all the available options.
Basic Syntax
The basic command-line syntax is:
pdf2svg [options] file1 file2 folder1 file3 ...
See more options in Command-Line Summary for PDF2SVG
General Usage Examples
Example 1. The simplest command line: Convert PDF to SVG.
Notes:
- The '-o' (or --output) parameter is used to specify the output folder. If this option is not specified, all converted SVG-s will be stored in the current working folder.
pdf2svg -o outfolder in.pdf
Example 2. Convert PDF to compressed SVG and without thumbnails and XML summary.
Notes:
- The '--noxmldo' option disables generation of thumbnails.
- The '--nothumbs' option disables generation of thumbnails.
- The '--svgz' option instructs PDF2SVG to compress SVG using GZIP compression.
- The '--verb' option instructs PDF2SVG to output more feedback in the console window.
pdf2svg --output test_out/ex2 --svgz --nothumbs --noxmldoc --verb 3 in.pdf
Example 3. Convert a password protected file to SVG.
Notes:
- The '-p' (or --pass) parameter is used to specify the password (i.e. 'secret') required to open the encrypted document.
- The '--pages' option instructs PDF2SVG to convert only the first page.
pdf2svg -p secret -o ex3 --nothumbs --noxmldoc --pages 1 secret.pdf
Example 4. Convert all PDF document in a given folders to stand alone SVG.
Notes:
- The '--bbox' parameter instructs PDF2SVG to use media box for clipping instead of crop box, which is the default.
- The '--embedimages' option (or -i in the short form) instructs PDF2SVG to embed all images as inline resources. This option produces stand-alone SVG files (i.e. SVG files without external references).
pdf2svg -o OUT --embedimages --box media "My Folder1" "MyFolder2"
Batch Processing and the Use of Wildcards
PDF2SVG supports processing of multiple input documents in the same run. For example, it is possible to specify multiple PDF folders and PDF2SVG will automatically process all PDF documents matching a given file extension. For example, the following command-line will process all PDF documents in folders 'test1' and 'test2'
c:\>pdf2svg -o c:/output_folder c:/test1 c:/test2
Wildcard characters can also be used to process multiple input files.
For example, if a directory contains the following PDF documents:
sh
To process all PDF documents in this folder, you could specify:
pdf2svg -o c:/output_folder c:/test1/*.pdf
To process all PDF documents starting with 'A', you could specify:
pdf2svg -o c:/output_folder c:/test1/A*.pdf
Or to process all PDF documents ending with '1', you could specify:
pdf2svg -o c:/output_folder c:/test1/*1.pdf
You can use either of the two standard wildcards --- the question mark (?) and the asterisk (*) --- to specify filename and path arguments on the command line.
The wildcards are expanded in the same manner as operating system commands. (See your operating system user's guide if you are unfamiliar with wildcards). Enclosing an argument in double quotation marks (" ") suppresses the wildcard expansion. Within quoted arguments, you can represent quotation marks literally by preceding the double-quotation-mark character with a backslash (\). If no matches are found for the wildcard argument, the argument is passed literally.
Exit Codes
To provide additional feedback, PDF2SVG returns exit codes after completing processing. The exit codes can be used to provide user feedback, for logging etc. This is particularly important for applications running in an unattended environment.
The following table lists possible exit codes and their description:
sh
All codes other then '0' indicate that there was an error during the conversion process.
To get detailed information on an error, set the --verb parameter to 2.
The following illustrates a sample Windows batch script that processes exit codes:
sh
XML Summary Document
This section describes the XML Summary Document that can be generated using PDF2SVG and its potential use in various applications.
By default PDF2SVG generates an XML Summary Document for every PDF document. The XML Summary Document contains document-level information that is not part of SVG files that describe individual pages. The information includes general information about the document (such as author, subject, title, keywords), as well as a listing of document parts and relationships such as pages, thumbnails, annotations, and bookmarks.
The following is a sample XML snippet generated by converting this user manual to SVG:
sh
Most of the elements and attributes are self explanatory. The 'info' element lists document information properties, the 'pages' element lists all 'page' elements that are part of the high level 'document', and the 'bookmarks' element specifies the outline tree that can be used for quick navigation between pages.
The summary document can be used as a map of the abstract document that contains many SVG files representing document pages, as well as outline tree and annotations describing how different document parts are related.
In most cases, the summary document is further consumed by an XML consumer/processor (e.g. XML DOM/SAX Library or XSLT). For example, an application may read XML summary to create database records for archiving purposes. Another application may implement interactive navigation through SVG pages using the document outline.
Yet another example of the XML wrapper consumer is an eBook generator that converts the XML Summary Document to HTML. The generated HTML would wrap converted SVG files and would provide web-based eBook interface for navigation between different pages, including bookmark tree, thumbnail index, etc. The end result would look like what is illustrated in the following figure:
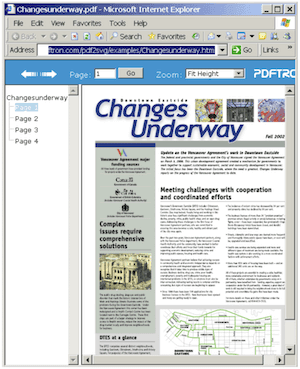
The process used to create HTML eBook wrapping converted SVG-s is illustrated in the following figure:
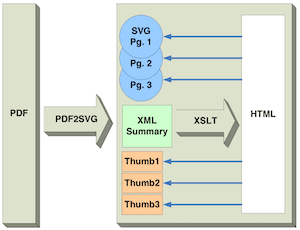
Using PDF2SVG, a PDF document is converted to a set of SVG images and their thumbnails, as well as the XML Summary Document. The fastest way to create HTML wrappers around SVG is using XSLT. XSLT is a very simple language for transforming XML documents. A simple XSLT transform may look as follows:
sh
The above XSLT template will create an HTML page containing general information about the documents such as it title, subject, keywords, etc. The HTML will also contain a thumbnail index of all pages in the document. Clicking on page labels or on thumbnails will open SVG graphics in the right pane of the browser window. The final result would look as follows:
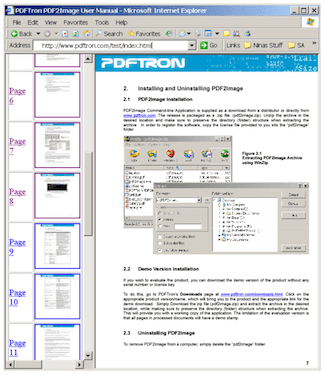
To run XSLT transforms you can use your favorite XSLT processor. As a starting point, PDF2SVG distribution comes with a sample project illustrating how to run XSLT transform using Microsoft .NET Framework.
Did you find this helpful?
Trial setup questions?
Ask experts on DiscordNeed other help?
Contact SupportPricing or product questions?
Contact Sales