Product:
Smart Data Extraction
Turn documents into AI-ready data — securely, accurately, and at scale.
Apryse’s Smart Data Extraction module transforms unstructured PDFs, scans, and DOCX files into structured, labeled JSON—built for downstream AI, analytics, or automation. Designed for developers, it offers SDK-first deployment across Windows and Linux, ensuring maximum privacy, flexibility, and control.
Whether you're powering a search feature, pre-processing data for a Small Language Model (SLM), or automating regulated workflows, Apryse gives you precision from page one.
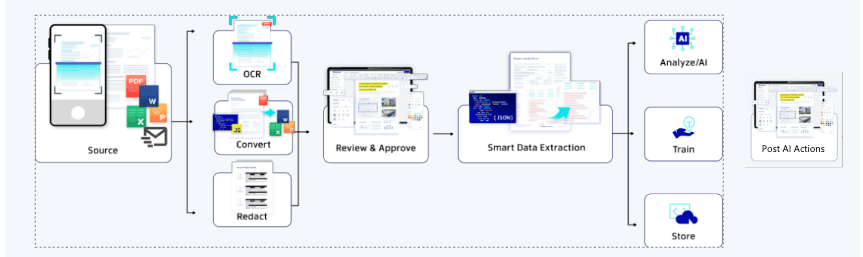
Key Use Cases
The Smart Data Extraction suite adds significant value across a range of workflows, including:
AI/ML training with structured document data
- Data extraction for analytics, AI-driven insights, and compliance
- Table and spreadsheet parsing at scale
- Form understanding and form field reconstruction
- Layout analysis for tagging, accessibility, or screen readers
- Content redaction or indexing with full visual fidelity
- JSON output for NLP, search, or app integrations
- AI/ML training with structured document data
- Domain-specific SLM pipelines (finance, legal, healthcare)
Core Capabilities
Smart Data Extraction supports four primary modes of intelligent extraction:
Tabular Data Extraction
- Extract tables from PDFs—even with merged cells or multi-row headers—and export to JSON or Excel for reporting, analysis, or AI.
Document Structure Recognition
- Parse the full logical structure: headers, footers, lists, images,styling,and paragraphs. Ideal for screen reading, content routing, transformation, or compliance workflows.
Form Field Identification
- Detect visual fields in flat PDFs and generate fillable interactive forms or structured JSON for onboarding or form reuse.
Key-Value Extraction
- Identify key-value relationships in documents with no explicit form layout. Extract data from invoices, resumes, and informal layouts without setting up templates or rules.
- Exclusive training to support key-value extraction on CAD and other technical drawing title blocks.
Document Classification
- Assign predefined categories to document pages based on their content and structure.
Note: If your goal is to convert PDFs into editable formats like Word, Excel, or PowerPoint, we recommend using Office conversion APIs.
Structured Output Format
All extracted data is exported in developer-friendly JSON. Each object includes page numbers and bounding boxes, making it easy to build overlays or highlight entities directly on the original document.
This format is ideal for:
- Visualizing extracted entities
- Enabling custom annotations
- Integrating with NLP pipelines
- Powering accessibility solutions (e.g., screen readers)
Preprocessing for Data Extraction
Before extraction begins, documents often need to be cleaned, normalized, or digitized. Apryse supports a full preprocessing toolkit—so your inputs are structured, accurate, and AI-ready.
These capabilities are modular and can be used independently or together, depending on your workflow:
- OCR (Optical Character Recognition)
Converts scanned or image-based PDFs into machine-readable text. - Deskewing & Despeckling
Cleans up crooked or noisy scans—improving OCR, table parsing, and layout accuracy. - Layer Flattening
Normalizes multi-layer PDFs for consistent rendering and analysis. - Rotation & Cleanup
Re-orients pages and removes visual clutter like stamps or overlays. - Redaction
Removes sensitive or unwanted content—ideal before sending data to AI or external systems. - PDF Conversion
Convert documents to HTML, Word, Excel, or JSON for labeling, annotation, or system integration.
These preprocessing tools improve downstream performance across:
- SLM training pipelines
- RAG and semantic search
- Compliance automation and classification workflows
No hallucinations. No unstructured text blobs. Just labeled, model-ready JSON.
Why Apryse?
- Fully offline and SDK-based—perfect for regulated environments
- No manual tagging or template creation
- Works on scanned, messy, or born-digital PDFs
Availability
The Data Extraction Module is available as an add-on for the Apryse SDK. It supports both Windows and Linux on desktop and server environments.
Evaluation Mode Limitations
- Maximum of 100 pages per extraction operation
- Random watermark page insertion
- Evaluation message may appear in JSON or Excel output
Get started
Smart Data Extraction Setup
Head over to the Set Up Guide to walk through installation, configuration, and how to run your first extraction
Set Up Apryse SDK Free Trial
New to Apryse? This guide will walk you through the steps to create your license key and begin creating your application.
Did you find this helpful?
Trial setup questions?
Ask experts on DiscordNeed other help?
Contact SupportPricing or product questions?
Contact Sales