Product:
Access PDF content to read, write & edit using JavaScript
Make sure you have Full API enabled in WebViewer.
To access PDF page content.
JavaScript
Read Elements Across All PDF Pages
Full code sample which illustrates how to traverse page display list using ElementReader.
About working with page content
Apryse SDK provides a powerful, easy-to-use API that can be used to read, write and edit text, images, and other graphical entities, called the Element API. A good match for interactive applications (such as PDF viewers and editors), for content extraction applications (such as PDF conversion and validation), and for dynamic PDF generation because the Element API is very efficient.
Page content, a major component of a PDF document, is made up of the visible marks on a page drawn by PDF marking operators. For details on PDF content streams and thorough operator descriptions please refer to Section 3.7.1, “Content Streams,” in the PDF Reference Manual.
Although the Apryse SDK SDF and Filter APIs provide everything required to decode and parse low-level content streams, using the Element API is easier and more intuitive. The reason why is that the Element API allows you to treat a page's contents as a list of objects (i.e. a display list or a sequence of Elements) rather than as sets of cryptic marking operators.
What is an element?
An Element (such as text, a path, or an image) is constructed from a set of marking operators from the page content stream. A set of Elements represents a display list.
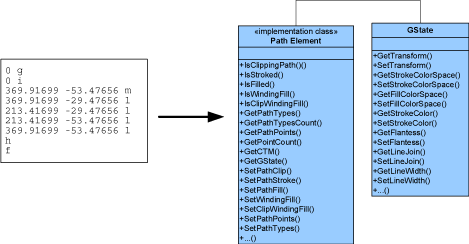
A sequence of page marking operators represents an Element.
Therefore, the Apryse SDK Element interface allows you to treat page contents as a list of objects whose values and attributes can be modified.
Using the Element interface, applications can read, write, edit, and create page contents and resources. These contents and resource may in turn contain fonts, images, shadings, patterns, extended graphics states, and so on.
An application may use Element methods to modify the appearance of a page, or it can create page content from scratch.
Each Element is independent of other Elements. Therefore, every Element encapsulates all the relevant information about itself. A text object, for example, contains all font attributes.
Element is the concrete base class for all Elements. Apryse SDK supports all content elements allowed by the PDF format, namely: path, text_begin, text, text_new_line, text_end, image, inline_image, shading, form, group_begin, group_end, marked_content_begin, and marked_content_end.
Note that some Elements — such as path, text, image, inline-image, and shading — represent concrete graphical elements. However, other Elements — such as text_begin/end, text_new_line, group_begin/end, and marked_content_begin/end — don't have graphical representation but are used for logical grouping of Element sequences or to provide meta-data associated with Element groups.
The Element class hierarchy implements a composite pattern — that is, the Element class provides the methods of all derived classes.

Element hierarchy. Only methods listed in the Element group or base class can be invoked for the given type.
To find the type of an Element object, use the element.GetType() method. Be forewarned: it is not allowed to call methods on an object that are not related to that object's Element type. The behavior when doing so is undefined. For example, it is illegal to call element.GetImageData() on an e_path element.
Note that, in above, e_group_begin/end and e_text_begin/end don't add any functionality to the common Element interface (i.e. GetType()/GetGState()/GetCTM()). The main purpose of these Elements is to mark sequences of Elements into logical groups. The Element e_group_begin corresponds to the PDF 'q' operator (saveState), e_group_end corresponds to the 'Q' operator, e_text_begin corresponds to the 'BT' (begin text) operator, and e_text_end corresponds to the 'ET' operator.
e_text_begin initializes a text object, initializing the text matrix and the text line matrix to the identity matrix. Because PDF text objects can't be nested, a second e_text_begin element cannot appear before e_text_end. A text object contains one or more text runs (that is, e_text elements) and new line markers (that is, e_text_new_line elements). e_text and e_text_new_line are not allowed outside of the text group (that is, outside element sequence surrounded by e_text_begin/end).
Graphics state
Every element has an associated CTM (current transformation matrix) and graphics state. Element.GetCTM() returns the transformation matrix used while processing the current Element. Element.GetGState() returns the element's associated graphics state. GState keeps track of a number of style attributes used to visually define graphical Elements.
The methods available through the GState class are listed below:
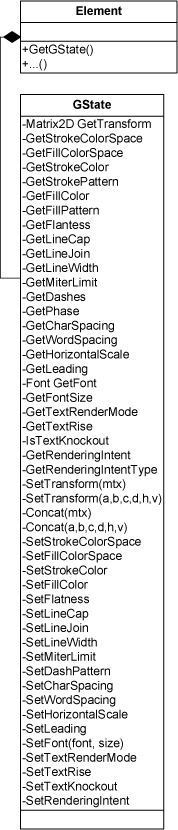
Graphics State.
For a detailed description of graphics state attributes refer to section 4.3 "Graphics State" in the PDF Reference Manual.
Did you find this helpful?
Trial setup questions?
Ask experts on DiscordNeed other help?
Contact SupportPricing or product questions?
Contact Sales