Product:
SDF / COS object model
Real-life PDF documents are much more complex than the "Hello World" PDF sample from the previous section. Streams in a PDF document can be compressed and encrypted, objects can form complex networks, and, in PDF 1.5, parts of the object graph can be compressed and embedded in so-called "object streams". All this makes manual editing of PDF documents extremely difficult — even impossible. The good news is that Apryse Systems released CosEdit — a graphical utility for browsing and editing PDFdocuments at the object level, offering unprecedented ease and control. Apryse SDK also provides a full SDF/COS level API making it very easy to read, write, and edit PDF and FDF at the atomic level. Furthermore, Apryse SDK also provides a high-level API for reading, writing, and editing PDF documents at the level of pages, bookmarks, graphical primitives, and so on.
SDF (Structured Document Format) and COS (Carousel Object System; Carousel was a codename for Acrobat 1.0) are synonyms for PDF low-level object model. SDF is the acronym used in Apryse SDK, whereas COS is a legacy word used in the Acrobat SDK.
In many ways, SDF is to PDF what XML and DOM are to SVG (Scalable Vector Graphics). The SDF/COS object system provides the low-level object type and file structure used in PDF documents. PDF documents are graphs of SDF objects. SDF objects can represent document components such as bookmarks, pages, fonts, and annotations, and so on.
PDF is not the only document format built on top of SDF/COS. FDF (Form Data Format) and PJTF (Portable Job Ticket Format) are also built on top of SDF/COS.
SDF.Obj
The SDF layer deals directly with the data that is in a PDF document. The data types are referred to as SDF objects. There are eight data types found in PDF documents. They are arrays, dictionaries, numbers, boolean values, names, strings, streams, and the null object. Apryse SDK implements these objects as shown in the following graph:
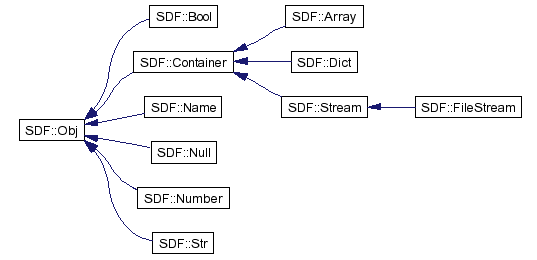
All objects ultimately derive from the Object class. Similarly, all SDF objects ultimately derive from the Obj class. Following the Composite design pattern, Obj implements each method found in its derived classes. Thus you can invoke a member function of any derived object through the base Obj interface. This object hierarchy is shown in the graph above.
If a member function is not supported on a given object (e.g. if you are invoking obj.GetName() on a Bool object), an Exception will be thrown.
In order to find out type-information at run-time, use obj.GetType() or obj.Is_**type**_() methods (where type could be Array, Number, Bool, Str, Dict, or Stream). Usually, an object's type can be inferred from the PDF/FDF specification. For example, when you call doc.GetTrailer(), you can assume that the returned object is a dictionary object because this is mandated by PDF specification. If an object is not a dictionary, calling a dictionary method on it throws an exception. These semantics are important for stylistic reasons — since type casts and type checks are not required, you can keep your code efficient and elegant. In case there is an ambiguity in PDF/FDF specification, you can use GetType() or Is_**type**_() methods.
As mentioned in the previous section, SDF objects can be either direct or indirect. Direct objects can be created using Obj.Create_**type**_() methods. The following example illustrates how to create direct number and direct name objects inside Dict objects. Note that the same approach will work for Array objects.
C#
New indirect objects can be created using doc.CreateIndirect_**type**_() methods on an SDF document. The following code shows how to create new Number and Dictionary indirect objects:
C#
Apryse SDK SDF provides many utility methods that can be used to efficiently traverse an SDF object graph. Here is an example on how to get to a document's page root:
C#
Because the PDF specification mandates that "Root" is always a dictionary, we can directly reference the "Pages" object by calling Get("key"). Also some so-called "PDF" documents can be corrupt from incompliance, meaning the document does not follow the PDF specification. In some corrupt PDF documents, the "Root" may be missing or may not be a dictionary object. In these and similar cases, the Apryse SDK throws an exception.
In order to retrieve an object that may or may not be present in a dictionary, use the dict.FindObj("key") method. For example:
C#
You can use DictIterator in order to traverse key-value pairs within a dictionary:
C#
To retrieve objects from an Array object, use array.GetAt(idx) method:
C#
In the previous section, we learned how to create indirect objects by calling the SDFDoc.CreateIndirect_**type**_() methods. Now, let's look at how to create references to those indirect objects. The following code shows how:
C#
So it's possible for multiple objects to refer to the same object. We call such objects shared objects. But shared objects must always be indirect objects. So if you want to share an object, it must have be created using SDFDoc.CreateIndirect_**type**_, or you should test Obj.IsIndirect() to make sure it's an indirect object.
Because the PDF document format disallows creating multiple links to direct objects, Apryse SDK will throw an exception should you try to create multiple links/references to a direct object. Here is an example below:
C#
In addition to the basic types of objects mentioned so far, PDF also supports stream objects. A stream object is essentially a dictionary with an attached binary stream. In Apryse SDK, all methods that apply to dictionaries apply to streams as well.
For a more complete discussion on Apryse SDK Filters see Apryse SDK Filters and Streams .
SDFDoc
Our overview of the SDF object model could not be complete without mentioning SDFDoc. SDFDoc brings together document security, document utility methods, and all SDF objects.
An SDF document can be created from scratch using a default constructor new SDFDoc() or from an existing file new SDFDoc(filename). It can be created from a memory buffer new SDFDoc(memoryFilter) or some other Filter/Stream as well. Finally, an SDF document can be accessed from a high-level PDF document using doc.GetSDFDoc().
Note that the examples above use sdfdoc.GetTrailer() in order to access the document trailer, which is the starting SDF object (root node) in every document. Following the trailer links, we can visit all low-level objects in a document (e.g. all pages, outlines, fonts, and so on).
SDFDoc also provides utility methods used to import objects and object collections from one document to another. These methods can be useful for copy operations between documents such as a high-level page merge and document assembly.
Did you find this helpful?
Trial setup questions?
Ask experts on DiscordNeed other help?
Contact SupportPricing or product questions?
Contact Sales