Product:
Extracting images from a PDF using JavaScript
Make sure you have Full API enabled in WebViewer.
To extract image content from a PDF document.
PDF image extraction
Full code sample which illustrates a few approaches to PDF image extraction.
About reading page content
Page content is represented as a sequence of graphical Elements such as paths, text, images, and forms. The only effect of the ordering of Elements in the display list is the order in which Elements are painted. Elements that occur later in the display list can obscure earlier elements.
A display list can be traversed using an ElementReader object. To start traversing the display list, call reader.Begin(). Then, reader.Next() will return subsequent Elements until null is returned (marking the end of the display list).
While ElementReader only works with one page at a time, the same ElementReader object may be reused to process multiple pages.
About Form XObjects, Type3 font glyphs, and tiling patterns
A PDF page display list may contain child display lists of Form XObjects, Type3 font glyphs, and tiling patterns. A form XObject is a self-contained description of any sequence of graphics objects (such as path objects, text objects, and sampled images), defined as a PDF content stream. It may be painted multiple times — either on several pages or at several locations on the same page — and will produce the same results each time (subject only to the graphics state at the time the Form XObject is painted). In order to open a child display list for a Form XObject, call the reader.FormBegin() method. To return processing to the parent display list call reader.End(). Processing of the Form XObject display (traversing the child display list) is illustrated below.
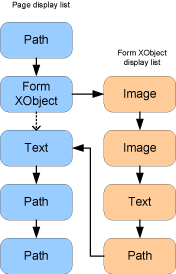
Note that, in the above sample code, a child display list is opened when an element with type Element.ElementType.e_form is encountered by the reader.FormBegin() method. The child display list becomes the current display list until it is closed using reader.End(). At this point the processing is returned to the parent display list and the next Element returned will be the Element following the Form XObject. Also note that, because Form XObjects may be nested, a sub-display list could have its own child display lists. The sample above shows traversing these nested Form XObjects recursively.
Similarly, a pattern display list can be opened using reader.PatternBegin(), and a Type3 glyph display list can be opened using the reader.Type3FontBegin() method.
Did you find this helpful?
Trial setup questions?
Ask experts on DiscordNeed other help?
Contact SupportPricing or product questions?
Contact Sales